
| スレッド表示 | 新しいものから | 前のトピック | 次のトピック | 下へ |
| 投稿者 | スレッド |
|---|---|
| webadm | 投稿日時: 2013-11-18 12:01 |
Webmaster  登録日: 2004-11-7 居住地: 投稿: 3084 |
2. Discrete-Time Signals and Systems 第二章からいよいよ本題、"離散時間信号とそのシステム"とでも訳せるだろうか。
この章では、これから当たり前のように前提とされる以下の基本的な概念の説明が行われている。 ・信号とは何か 音声とか画像とか、一つ以上の独立変数を持つ関数として数学的に表すことができるもの ・信号はどのように表されるか 音声信号は時間を変数とする関数で表される。 画像信号は平面上の座標の輝度や色に対応する2つの変数を持つ関数として表される ・信号処理システムとは何か 連続時間系と離散時間系の二種類がある。 アナログ信号処理システムは全て連続時間処理。 デジタル信号処理システムは後者だが入力と出力にはアナログ信号処理が不可欠。 なので本書では離散時間信号処理に範囲を絞るためそれをテーマとする。 ・離散信号処理系の特徴 LTI(線型時不変)が前提。 それによって系が定係数型微分方程式で記述できる。 時間領域と周波数領域のどちらでも扱える。 後続するセクションで上記の概念を詳しく扱う |
| webadm | 投稿日時: 2013-11-18 12:47 |
Webmaster 登録日: 2004-11-7 居住地: 投稿: 3084 |
2.1 DISCRETE-TIME SIGNALS ここでは離散時間信号の概念を学ぶ。
最初に著者は昔からの伝統的な解説を試みているが、ここで躓く人も少なからず居る。 実は離散時間信号の概念は決して新しいものではなく、人類は太古から何らかの形で離散時間の概念を持っており、生活に知らず知らず利用してきている。 例えば天文学者らは、古代から離散時間で天体を観測してきた。観測できる時間帯は一日のうち夜に限られるし、必ずしもその日の地球の自転が所望する天体が位置する天球を向いているとは限らないので、一年を通じて観測できるタイミングは数える程しかない。それでも観測データを多年に渡って積み重ねることによって天球表面を移動する惑星の軌跡を辿ることができた。 一般人も季節が周期性を持ってやってくることを生まれ育つ中で周囲から学んで行く。その季節になるとそれぞれ筍の行事が行われたりすることで、ああまた今年もこの季節になったかとその後の一年の計画を立てることに役立ててきた。 農耕や畜産でも、作物や家畜の状態を始終隙間なく見ているわけにはいかないので、周期的に離散時間的に手入れしたり餌をやったりする時に作物や家畜の状態の変化を知ることになる。 人口の増減も連続時間ではなく離散時間で発生し観測される。なので人口の統計データは離散時間的な信号となる。 証券売買や先物取引相場も連続時間系ではなく離散時間系である。市場は24時間365日開いているわけではなく、また売買も連続時間で進行するわけではなく、離散時間で処理される。処理できる最小時間間隔も短くなってきているがそれでも技術的な限界がある。 相場のグラフは離散時間信号となる。 生体の信号処理も連続時間系ではなく離散時間系である。生体はアナログ系であるが、こと神経系の信号伝達は神経細胞の興奮パルスの伝達という形で離散的な信号を使って行われている。これは生体内でわずかの電気信号で情報を伝える必要から、ノイズに強い離散信号が自然と選択されたことを意味する。もしアナログ的な連続時間系だったら、環境の変化や体温の変化だけで影響を受けてしまってまともな情報が得られないことは明らかである。生体の信号処理はデジタル信号処理とはかなり異なったシステムになっている。伝達はパルス信号で行うが、その後の演算は連続時間系である。必ずしもデジタル信号処理が前提とする線型時不変でもないから、時と状況によって演算結果が変わってくることもある。それが生き物の多様性を生み進化と生き残りのコツなのかもしれない。 こんなことはテキストには書いてないけど持論である。 さて本書の内容に戻ろう。 ここで初めて数式らしきものが登場する。 おそらく大半の人はすぐには最初の数式すら理解できないだろう。 ここでは既に暗に集合論(集合と写像)や位相の概念が身に付いていることを著者は前提としているように思われる。 著者は数列内のn番目の数をx[n]で表している。 まずもって数列とは何かとかを知らないとここで躓く。 数学を有る程度学んだ者なら常識の範疇だが、そうでない人にとっては意味不明な言語表現にしか写らない。 ここで解説を試みよう。 数式はある種のプログラミング言語みたいなもので一定の表記と解釈のルールがある。それを知っているのと知らないのとでは数式の意味を即座に誤りなく解釈できるか否かの違いがある。 =(等号)記号は左を右の記述で定義するという機能がある。プログラミング言語だと代入とか呼ばれているけど、それはそれを解釈したプログラムが以降左のオブジェクトが現れたら右で定義されたオブジェクトと見なすという機能があるからだ。 左側のxは数学では変数、パラメータ、係数とか色々なオブジェクトを代表するシンボルとして任意の文字や記号が使える。 右側の{}でくくられた部分が定義するオブジェクトの範囲や条件を与える。ここではx[n]とだけあり、更に左の方にnの取りうる条件範囲が付記されている。nはおそらく整数だと思われるが、整数の全ての範囲を含むという意味である。 ということで上の式を解釈すると、 "これ以降xと書いた時には、無限個の数列を意味する" ということになる。言葉で書いた方が判りやすいが、数式や記号で書いた方が文字数が少なく、必要十分な情報を読者に伝えられるというわけである。ただ異なる記号表記や数式表記のルールを持つ者同士では話しが通じないばかりか、誤解を生む可能性も無きにしもあらず。なにせそのルールを教えるのは人間様だから、ひとそれぞれだし。 つまりxは離散時間信号データの集合そのものであることを意味する。信号は順番に記録されるとすると、それが順番に並んでいるので、何番目に記録した値かはそのインデックスを与えれば対応する値がすぐに引き出せるということになる。 コンピュータプログラムなら、テキストファイルの中の文字だったり、数値データファイル中の数値データだったりする。ファイル先頭からのインデックスを指定すれば、その位置の文字や数値が一意的に定まるというもの。もしくはインデックスで参照できる一次元配列のようなもの。二次元配列なら行とカラムの2つのインデックスを指定すれば一意的にデータが定まる。 小学校で言えば席順みたいなもので、誰がどこに席に座るかはクラス編成時に決まるから皆勝手な位置には座らない(海外ではどうか知らないが少なくとも昔の日本ではそうだった)。先生は席の場所でそこに誰くんや誰ちゃんかを一意的に識別できる。前から何列目で右から何番目とかいう感じ。 このへんも著者によって表し方はまちまちになるところだと思われる。 さて離散時間信号が上で表されたとして、それはどうやって生成されるかというと、アナログ信号を離散時間で標本化することによってである。 それをまた著者は以下の数式で表している ここで新たにxs(nT)なる謎の記述が登場する。著者はこれを時間を変数とするアナログ信号値を返す関数としている。xa(t)は連続時間系の関数でtは実数で表された時間をとる。混乱してしまうのだが、実時間でのアナログ信号値は時間など指定できないのだけど何故?と疑問に思うかもしれない。これは数学的に実時間信号を扱うための方便であると考えたほうが良い。誰も実時間の世界で未来の時間を指定して未来のデータを得ることなどはできない。それは予め承知のことと察するべし。 つまりは数学的に集合論でもって、離散時間信号が実時間のある離散時間での値に一対一で対応しているということを言いたいのだと解釈しよう。 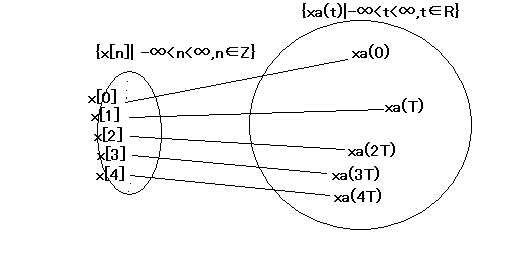 もともと標本化できるデータ数が有限であること、または標本化できる時間間隔の最小間隔に限界がある、などの理由から実世界のデータを何らかの形で情報を出来るだけ損なうことなくどこまで端折れるかというのが標本化理論の発端であると思われるので、出来るだけ端折れるなら端折って少ない量のデータで必要な情報が得られればそれにことたことはないわけである。 またTは標本化周期(Sampling frequency)と呼んで居る。 また暗にx[n]はnが大きくなるにつれ最新のxa(nT)に対応するということになっている。なかなか最初から全部を数式で表すことはできないのだな。一度この概念が理解すれば、それ以降はx[n]だけを対象とするので問題ないのだろう。 プログラム言語での配列とかは整数でしかインデックスできないが、FORTRANとかでは配列のアクセスと関数のアクセスの記述に区別が無いので学生はxa(nT)とx(n)とがどちらも関数のように思えてしまうかもしれない。C言語では配列はx[n]と関数参照とは異なるのでこの混乱は無い。x[n]にnが実数だったらコンパイラに怒られる。 集合と写像の概念では当たり前だが、xの中には当然ながらまったく同じ値が割り当てられていることがある。なのでnを特定すればそれがいつ標本化サンプルされた値が割り当てられているか知ることはできても、逆は成り立たない。すなわち標本化された値からそれが何時もしくは何番目に標本化されたものであるかは一般的には特定ができない(少なくとも2つ以上同じ値を持つ標本化データが存在する場合)。 上の集合と写像の図で言えば、右と左の集合のどちらでも同じだけど、値だけ取り出して、さてそれが何時標本化されたものかどうかは知ることはできないということである。左で言えば何番目に標本化されたものと指定すればその時のデータが特定できるが逆は不可。右の集合では、任意の実数時刻のデータを拾っても、それに対応するxのデータが存在するとは限らない。つまり標本化の写像は全射ではなく、単射でしかない。 さて上の集合図で言えば、右のxa(t)の集合は無限集合で隙間なくびっしりと値が詰まっている。なので例え有限時間でも全ての情報を記録しようとすると無限の情報量となってしまうので現実には不可能。 えー、それじゃアナログ時代のテープレコーダーとかは全部記録しているんじゃないの? という疑問が湧くのは当然である。 そういえばアナログ音源としてレコードなんてものもあったよね。あれはどうなの。無限の情報量を記録しているんじゃないの? 現実にはアナログ記憶方式でも情報は端折って記録しているんじゃ。端折り方がアナログ的なだけである。つまり有限の周波数領域の情報だけを記録することによって情報量を有限に抑えているのである。 なーんだそういうことだったのね( ´∀`) 実は時間領域で離散時間で標本化して情報量を有限数に端折ることは、周波数領域でアナログ的に帯域幅を端折るのと同じであることを後で学ぶことになる。標本化理論の要ね。 著者は標本化によってたった32m秒の音声信号でも本来は無限数の情報を持つものを、離散時間で256個に標本化することで情報量を有限に抑える図を示している。こうして標本化されたデータから元のアナログ信号を復元する理論(標本化定理)については第4章で学ぶと触れている。 著者は続けて、標本化処理について数学的な記述を示している。 まずは単位標本化数列(unit sampling sequence)という以下の特殊な数列を導入する これはx[n]と似ているが、nを変数とする特殊な関数と考えても良く、n=0以外は値0で、n=0のときだけ、かつそのときに限り値1を持つ。 これを用いることによって標本化数列が以下の様に数学的に記述することが容易になる利便がある。 著者はa3のところがa_3に誤記しているが、校正時に見逃してしまったのかもしれない。Latexで余分に_を入れてしまったに違いない。上の式ではnを指定すると数列p[n]の中からそれに対応する標本化データを抽出できることを確認できる。この形にすれば、標本化数列を数式で表すことができる。 著者は標本化数列を用いてx[n]を以下の様に再定義している これによってnが決まれば一意的に標本化信号値が決まることになる。これも漫然と眺めていては理解したことに成らないのではなかろうか。δ[n-k]はn-k=0のとき、ただそのときだけ値1をとるので、k=nになった時だけ総和はx[k]の値となる。それ以外のkでは0を無駄に加算するだけで総和に影響を与えない。 また標本化数列を用いることで任意の関数の標本化を行うことができる。 例えば、以下の単位ステップ数列 は以下の様に記述できる ちょっと数学的になってきたのでここで躓く人も多いかと思う。 先のδ[n]の定義と睨めっこすれば、k=0の時だけδ[k]=1でそれ以外のkではδ[k]=0であることはわかる。ここで総和の上限が∞ではなくnであることに注意。n<0以下ではまだ0ばかりの総和にしかならないが、n≧0となると、k=0の時に1が加わり、それ以降は0になっても総和は1のまま変わりない。従ってx[n]は単位ステップ数列を返すことと同値である。 上の式の総和を展開すると ということになる。これなら少しわかるかもしれない。n<0の場合には、どの項も0なので総和も0、n≧0の場合は一つだけ1の項があるので総和は1になる。 単位ステップ数列を数式で表すのは別に上の方法だけではない 単位標本化数列を使って再定義されたx[n]のようにδ[n-k]というシフトテクニックを使うと総和の上限数をnでなく∞にすることができる。 これもx[n]の再定義の時と同様にn-k=0の時だけすなわちn=kの時だけδ[n-k]は1をとりそれ以外は0であるから総和が1になるというもの。 (2013/11/18) いきなり離散系の表記で始まって、電気回路理論おもちゃ箱ではもっぱら連続時間系の数学ばっかりだったのでギャップが激しい。 しかしよく見ると連続時間系で学んだことと対称な世界であることがわかる。そこで連続時間系から離散時間系を眺めてみると、単位標本化数列のδ[n]というのは連続時間系ではDiracのδ関数が対応する これはすでに詳解電気回路演習(上)の最後の章で標本化定理が出てくるのでその時に学んだ覚えがある。連続時間系から見ると標本化数列というのは ということだった。 そこで著者の最初の標本化数列の式につながる。 単位ステップ数列に対応するのが連続系の単位ステップ関数である、 朗報がひとつある、離散系では連続時間系でうんざりするほど登場した積分記号は完全に姿を消し、代わりに総和記号がうんざりすぐほど登場することだ。どちらにしてもうんざりしないように。 著者は続いて衝撃数列(インパルス数列)というのを離散系で記述している これは連続時間系では単位ステップ関数を微分するとインパルス関数であるδ関数になるのと対応する 連続系では微分と積分でだいぶ悩まされたけど、離散系ではひとつ前のものとの差分をとるだけの簡単なものとなる。これはもうひとつの朗報だ。 著者は更に離散時間信号処理で頻繁に出てくる数列について触れている。 それは指数数列で、簡単なものでは という形式を持つ。 aの絶対値が1未満なら、標本化数列は次第に減衰していく。Aが負の場合には極性が逆になるが、やはりaの絶対値が1未満なら次第に0に近づいていく。aの絶対値が1より大きい場合には次第に0から離れていき絶対値が増大していく。 上の形式でAやaが複素数を取るケースは重要な要素なので今のうち目を慣らせておくのが良いという著者の老婆心が見え隠れする。 これも|a|が1より大きい場合、振幅は増大していく、|a|が1未満なら振幅は減少していく。 |a|が1の場合には ということになる。 連続時間系の場合にはこれは正弦関数となって周期関数なのだが、離散系の場合には少し事情が異なるところがある。 連続時間系ではびっしり隙間なく連続的な時間軸なので角周波数ω0の単位はradianでよかったが、離散系だととびとびにしか時間が存在しないのでω0は標本化毎のradianということになる。 また周期性に関しても、連続時間系の位相にあたるφが2πの場合には、 ということになる。従って ということになる。 連続時間系では正弦関数は2π毎に繰り返すのに対して、離散時間系でいうと繰り返し数列というのは が成り立つような数列である。 Nは繰り返し周期で整数でなければならないことは明らか。 離散時間の正弦関数で が成り立つためには であり、かつそのときに限る。 複素指数関数についても同様 \omega_0の値によっては標本化数列は周期的であることもあるし、そうでないこともある。 著者は例を挙げてそれを示している 標本化すると周期数列になるケース 周期数列にならないケース これはx1[n]ではω0が2π/8だったのをx2[n]では3π/8に増えているので、周期Nが8ではなく16でなければならないためである。 標本化の周期と実際の信号の繰り返し周期とは一般に一致しないので、周期が最も短い繰り返し信号成分よりも長い場合には、それを復元することはできないことは予想できる。 デジタルオシロスコープで、観測する正弦波の周期よりも十分短い(10分の1以上)場合でないと、入力信号の繰り返し周期が正しく観測できない。入力信号の周期に近づけば近づくほど、サンプリングしたデータをプロットして現れる波形は元の信号の繰り返し周期より長くなったように見える。この現象を意図的に利用したのが、サンプリングオシロスコープというまったく別の用途の測定器があり、それは標本化周期は実際の繰り返し信号波形の周期より長いが、位相をずらしていくことで長い目で見ると入力信号の繰り返し周期より十分短い周期で標本化したことになる。これは入力信号が安定した繰り返し信号であることが前提である。 話しは変わって、標本化の定式化について突っ込みを入れておくことにする。 標本化のタイミングは周期の整数倍ということで離散化しているが、現時点では標本化されたデータについては実数のままである。従ってその値の取り得る範囲は-∞から+∞でその間びっしりと無理数も含めて無限個の値を取り得るということになっている。 実際のデジタル信号処理システムでは、入力信号は標本化された時点でA/Dコンバーターによってデジタル値に変換される。これは連続な実数空間からとびとびの離散化空間に近似変換されることを意味する。この時点で近似変換された時点で小さな実数端数値が失われたり加えられることになる。これは入力値に依存するのでランダムであると考えても良い。つまり意図しないノイズが標本化した時点で加わることになる。このややこしい事情は通常は後回しにして、初等の段階では形式的に標本化値は実数のままとするのである。後にこの問題を量子化雑音ということで扱うことになる。 有名な標本化定理も標本化されたデータは実数値としている。そうでないと成り立たない理論である。 デジタルオーディオとかも実は音源からデジタル信号列に標本化した時点で量子化雑音が織り込み済みである。標本化したデータのビット数を大きければ量子化雑音のレベルは相対的に小さくなるものの無くなるわけではない。オーディオオタクはこの点を気にしていて、ディジタルオーディオもHDでないと気が済まない理由はそこにある。また標本化周期に揺らぎがあると、復元時も含めて源信号には存在しないノイズが生まれることになる。ここもオタクは気にして、揺らぎが少ないクロック発信源を使うことにこだわったりするわけである。どれぐらい揺らぎがあると源信号にはない雑音がどれだけ生じるかは解析してみないとなんとも言えない。これも初等レベルでは難し過ぎるので後々の課題ということになる。 例えHDのディジタルオーディオでも、音源の音圧レベルはメゾピアノからメゾフォルテまで広いので、コンサートの最初から最後までデジタルサンプリングで録音しようとするとダイナミックレンジが問題となってくる。フルレンジをメゾフォルテに合わせると、メゾピアノは0に近いごく一部分の低い範囲しか標本化データ値が取り柄無いことになる。そうすると量子化雑音が相対的に大きくなるので音が悪くなる。フルレンジをメゾピアノに合わせると、それよりも音圧が高くなるとレンジオーバーで音が歪んでしまう。演奏状況に合わせてダイナミックレンジを変えると、演奏中にあったはずの抑揚が完全に失われてしまう。理想的にはダイナミックにレンジを適応させて、その情報も合わせてデジタル化記録するというのがあるが、それをどうやって再生(復元)できるのかは課題が残る。そもそも標本化理論の想定外の標本化方式だし。もちろん一定周期の標本化以外の標本化方式がないわけではないが標本化定理のようにちゃんと源信号が復元できるという理論を新たに証明する必要がある。それも初等的な課題を超えるので、おそらくは本書でも扱わないであろうと思われる(問題点には当然触れると思われるが、解決法については読者の課題としているはず)。 デジタルオーディオの場合は、なるべく演奏開始から終了までのあいだダイナミックレンジが一定で済み、かつダイナミックレンジをフルに使うような信号パターンの音楽がノイズが少なく良く好まれる理由もそこにある。ダンスミュージックとかテクノ系の同じビートの繰り返しが続くものがそれにちょうど該当する。どちらかというと音源もデジタル音源でミキシングもPCソフトで作り込みという音楽が好都合。生演奏や生録音はそれよりもはるかに納得する音作りが難しい。それに生演奏や生録ものは歩きながらイヤホンやヘッドフォンで聞く場合に、周囲のノイズに音楽がかき消されてしまいやすい。生演奏ものは音のエネルギー密度が疎であるためである。それに対してコンピューターで作り込んだものは最大限まで塩をきかせる音のエネルギー密度の高い曲作りが可能である。 |
| webadm | 投稿日時: 2013-11-24 17:32 |
Webmaster 登録日: 2004-11-7 居住地: 投稿: 3084 |
2.2 Discrete-time System 次は標本化されたデータを入力としてそれを処理して出力する離散時間系システムについて学ぶことに。
一般的に広義のデジタル信号処理システムは数式で以下のように定式化することができる ここでxは以前に定義した離散入力信号の集合、Tは任意の信号処理変換で、yはxをTで信号処理した結果の離散出力信号の集合。 これによって画像処理も広義の信号処理含まれる。 著者は離散時間系だけに限定して以下のように定式化している。 ただしこの定義でもnが標本化された画像領域区間を左上端から右端、そして右端から次ぎの行の左端へと順番をふったものとすれば画像処理も含まれることになる。 連続時間系ではnは標本化周期の時間順に割り当てられた番号ということになる。 それを制御系とかでよく登場するブロック図で表すと 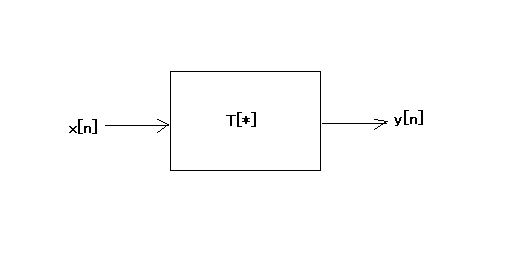 ということになる。 これに対して連続時間系システムでは 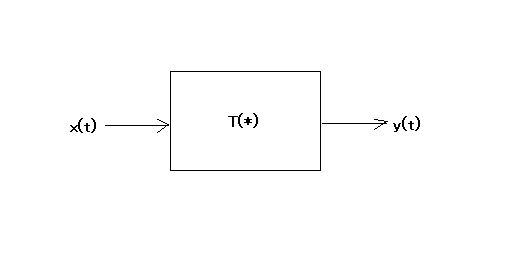 ということになる。 連続時間系では待ったなしに時間が変化するのに応じて出力も変化するが、離散時間系では、標本化周期毎にしか入力および出力は変化しないことになる。 先のブロック図だと離散時間系は同時期に1つの標本化入力に対して出力を一対一で変換するだけのように見えるが、連続時間系のように変換Tの中には積分変換や微分変換などの過去の入力に依存する演算が伴うことも当然予想される。連続時間系の積分演算は離散時間系では総和に、微分は差分に対応すると学んだ通りに、離散時間系システムでも同様の演算が伴うことが可能であると考えるのが自然である。つまり、現在とそれより前の標本化入力の集合を入力としてそれに対して変換したデータ列を出力すると考えるのが自然であるような気がする。当然のことながらある時点より前に出力された結果は、それ以後の入力によって変わることはないという制限はつく。これは連続時間系システムにおいても同様であり、過去の結果を書き換えることはできないからである。もちろん入力と出力の標本化の単位が違えば、複数の標本化入力の後にひとつの出力を行うという離散時間システムもあり得る。機械翻訳システムが実現すれば、入力は標本化された音声データで、出力は翻訳された単語フレーズ信号列になるかもしれない。いずれの場合でも一度出力してしまった結果を、後から与えられた入力に依存して変えるということは出来ないという制限はある。同時通訳でも、一度口にしてしまったものはもう取り消すわけにはいかないので難しいところである。日本語の場合には重要な言葉が最後に来るので翻訳が難しいかもしれない、”我々は君たちを無視している"、"わけではない。"というのをリアルタイムに翻訳しようとすると最後のフレーズが入力されときに難しい局面が生じる。英語の場合にはこれと逆になるが、最初に結論が来て細かい補足が後からくるので翻訳もやりやすい。 (続く) |
| スレッド表示 | 新しいものから | 前のトピック | 次のトピック | トップ |
| 投稿するにはまず登録を | |
