
| フラット表示 | 前のトピック | 次のトピック |
| 投稿者 | スレッド |
|---|---|
| webadm | 投稿日時: 2013-11-24 17:32 |
Webmaster  登録日: 2004-11-7 居住地: 投稿: 3113 |
2.2 Discrete-time System 次は標本化されたデータを入力としてそれを処理して出力する離散時間系システムについて学ぶことに。
一般的に広義のデジタル信号処理システムは数式で以下のように定式化することができる ここでxは以前に定義した離散入力信号の集合、Tは任意の信号処理変換で、yはxをTで信号処理した結果の離散出力信号の集合。 これによって画像処理も広義の信号処理含まれる。 著者は離散時間系だけに限定して以下のように定式化している。 ただしこの定義でもnが標本化された画像領域区間を左上端から右端、そして右端から次ぎの行の左端へと順番をふったものとすれば画像処理も含まれることになる。 連続時間系ではnは標本化周期の時間順に割り当てられた番号ということになる。 それを制御系とかでよく登場するブロック図で表すと 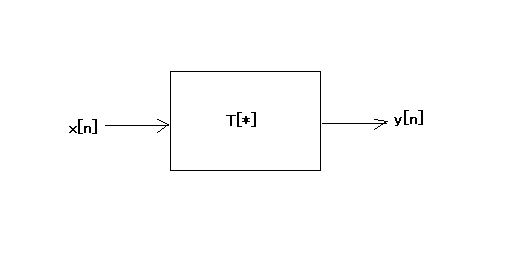 ということになる。 これに対して連続時間系システムでは 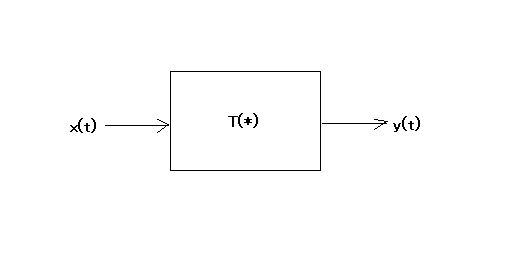 ということになる。 連続時間系では待ったなしに時間が変化するのに応じて出力も変化するが、離散時間系では、標本化周期毎にしか入力および出力は変化しないことになる。 先のブロック図だと離散時間系は同時期に1つの標本化入力に対して出力を一対一で変換するだけのように見えるが、連続時間系のように変換Tの中には積分変換や微分変換などの過去の入力に依存する演算が伴うことも当然予想される。連続時間系の積分演算は離散時間系では総和に、微分は差分に対応すると学んだ通りに、離散時間系システムでも同様の演算が伴うことが可能であると考えるのが自然である。つまり、現在とそれより前の標本化入力の集合を入力としてそれに対して変換したデータ列を出力すると考えるのが自然であるような気がする。当然のことながらある時点より前に出力された結果は、それ以後の入力によって変わることはないという制限はつく。これは連続時間系システムにおいても同様であり、過去の結果を書き換えることはできないからである。もちろん入力と出力の標本化の単位が違えば、複数の標本化入力の後にひとつの出力を行うという離散時間システムもあり得る。機械翻訳システムが実現すれば、入力は標本化された音声データで、出力は翻訳された単語フレーズ信号列になるかもしれない。いずれの場合でも一度出力してしまった結果を、後から与えられた入力に依存して変えるということは出来ないという制限はある。同時通訳でも、一度口にしてしまったものはもう取り消すわけにはいかないので難しいところである。日本語の場合には重要な言葉が最後に来るので翻訳が難しいかもしれない、”我々は君たちを無視している"、"わけではない。"というのをリアルタイムに翻訳しようとすると最後のフレーズが入力されときに難しい局面が生じる。英語の場合にはこれと逆になるが、最初に結論が来て細かい補足が後からくるので翻訳もやりやすい。 (続く) |
| フラット表示 | 前のトピック | 次のトピック |
| 題名 | 投稿者 | 日時 |
|---|---|---|
| |
webadm | 2013-11-18 12:01 |
| |
webadm | 2013-11-18 12:47 |
| » |
webadm | 2013-11-24 17:32 |
| 投稿するにはまず登録を | |
